Getting LLMs to reason with Types
The reason why LLMs are programmatically useful is because they can produce structured outputs. They’ve become good over the years of producing these outputs accurately, but smaller (cheaper) models used mostly for data extraction still struggle when given complex object shapes.
Usually, to guide the LLMs to produce these outputs, developers prompt with a fully qualified JSON schema, or a JSON example with sample data.
For example, a popular way of producing JSON schemas are:
- Python: Pydantic models ->
model.model_json_schema() - Typescript: Zod schema ->
zodToJsonSchema()(A third-party packagezod-to-json-schemathat helps you do this)
JSON Schemas can represent complex validation logic, the same representation sent to the model can be used to validate the output, but are verbose and costs a lot of input tokens.
Examples JSON is less verbose, but you have to maintain a validation spec that is different to the example sent to the LLM, leading to schema drifts. They don’t scale well in large codebases.
Questioning JSONSchema
JSON Schemas are ubiquitous, well-understood, and has great interoperability. However, I suspect that LLMs have see more instances of Typescript types <-> JSON object conversions, than JSON Schema objects. This is because Javascript objects (save for a few edge cases like undefined) neatly map to a JSON representation without a custom serialiser. In fact, you can JSON.stringify a Javascript Object and JSON.parse it without much drama.
Therefore, I think Typescript Types are much more well-understood by LLMs than JSON schemas. They should be more prevalent in the training data than the JSON schemas.
Given the following json schema:
{
"type": "object",
"properties": {
"name": {
"type": "string",
"minLength": 2
},
"email": {
"type": "string",
"format": "email"
},
"age": {
"type": "number",
"minimum": 18,
"maximum": 120
},
"roles": {
"type": "array",
"items": { "type": "string" },
"minItems": 1
}
},
"required": ["name", "email", "age", "roles"]
}
Can we shorten it to something like:
{
name: string /* name=>name.length>=2 */,
email: string /* email=>email.includes("@") */,
age: number /* age=>age>=18&&age<=120 */,
roles: [string] /* arr=>arr.length>=1 */
}
Data Validation with a Typescript Types
Challenge 1: Runtime Accessible Types
Typescript Types are not runtime accessible. They are completely stripped in transpilation. Therefore, we’d have to build a pydantic-esque (or zod-esque) model builder, that produces Typescript types.
Challenge 2: Representing Validations
Typescript types also cannot represent complex validation scenarios. Therefore, we’ll have to represent the validators in a way that the model can understand, and has the least amount of impedance mismatch between how they are defined and how they are represented in the schema.
Challenge 3: Deserialisation and Validation of the output
When the model gives the output, we’ll have to parse the object, and run all the validation functions.
StructLM
To test this out, I built StructLM, as a Typescript native library. Why Typescript? Again, this is my hunch that LLMs have seen a lot of Javascript arrow functions and Typescript types than any other comparative programmatic construct.
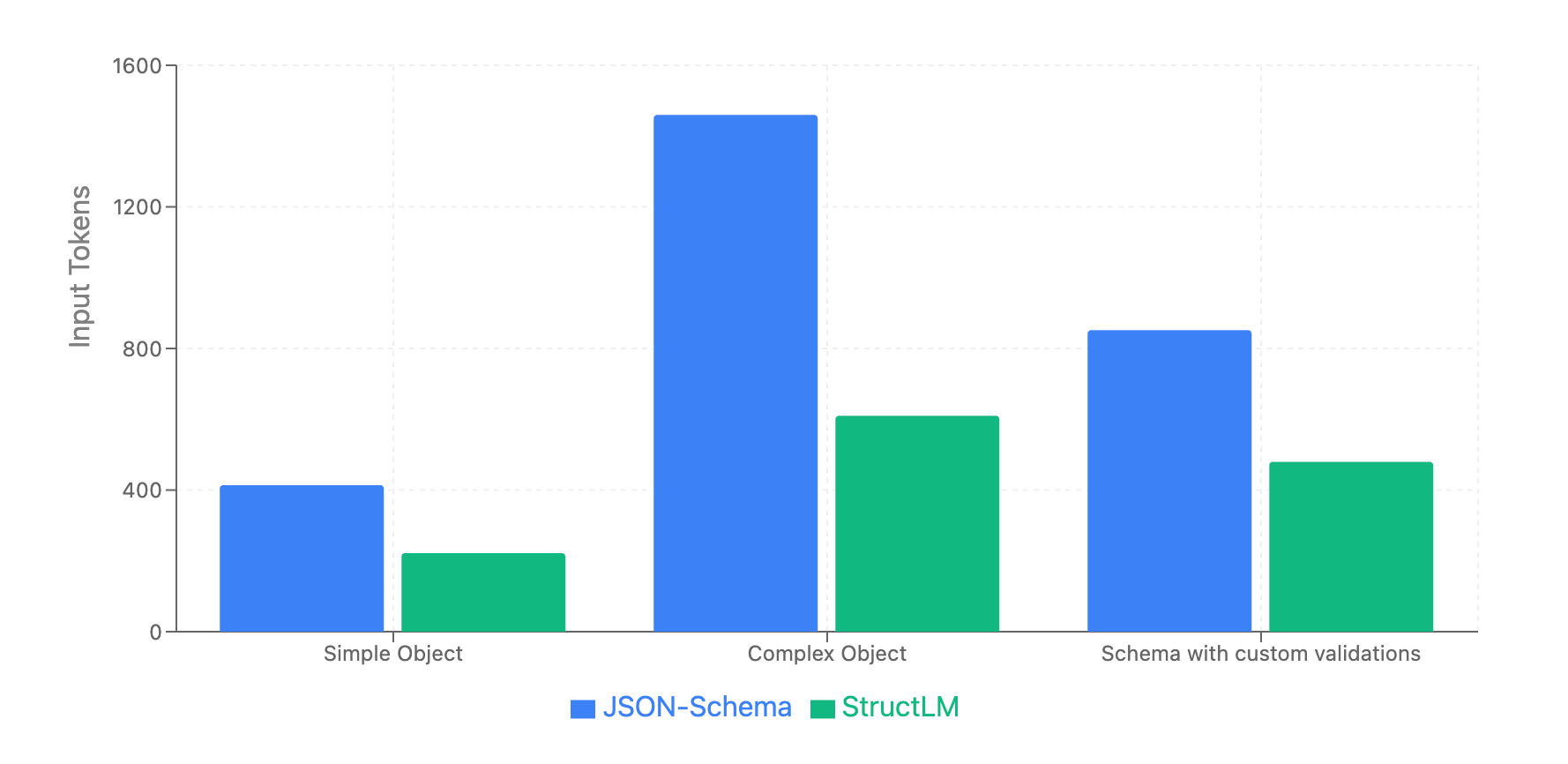
I ran a few benchmarks and it shows 30%-40% token saving on the JSON schema, with no accuracy loss. In fact, the accuracy is marginally improved (since the LLM has to do less work to decipher the schema).
This is what the token savings for Haiku looks like:
In addition to JSON schema, StructLM also has a few other advantages when working with Typescript.
- Validations are more expressive, and can be represented as Javascript functions. (Caveat: The functions need to be pure, to be stringified properly)
- The resulting schema is Type-safe, and can be used as a normal type in rest of the codebase.